
Local AI Design Lab: Agentic Workflows
Ran open-source LLMs locally on Apple Silicon, primed them on internal MuSo content, and deployed role-specific design agents that first-drafted live exhibit missions with zero cloud dependency.
 Museum of Solutions
Museum of Solutions Most AI tools are cloud-dependent, generic, and disconnected from the specific context and language of a design practice.
Built a local AI lab using Ollama and OpenWebUI on Apple Silicon. Primed models on internal MuSo documents. Connected LLMs to Stable Diffusion. Designed role-specific agents for distinct creative tasks.
One of four active Investigation Zone missions first-drafted by the trained model. The first draft of Lost Code of Play produced by the same system. Two AI systems talking to each other — locally, with no cloud dependency.

Setting Up the Local Stack
Installed Ollama on a Mac Studio (M1 Ultra, 64GB RAM) to run LLaMA 3, DeepSeek, Qwen, and Phi locally using Apple Silicon's GPU acceleration. Built the interface layer with OpenWebUI — an open-source ChatGPT-style frontend with account handling, prompt storage, and system prompt configuration.
Contextual Priming
Fed foundational MuSo documents — project briefs, spatial design philosophies, mission structures, tone-of-voice guides — into the LLM's prompt memory. Not fine-tuning, but systematic contextual priming that turned a general model into a MuSo-aware creative partner.
Connecting Two AI Systems
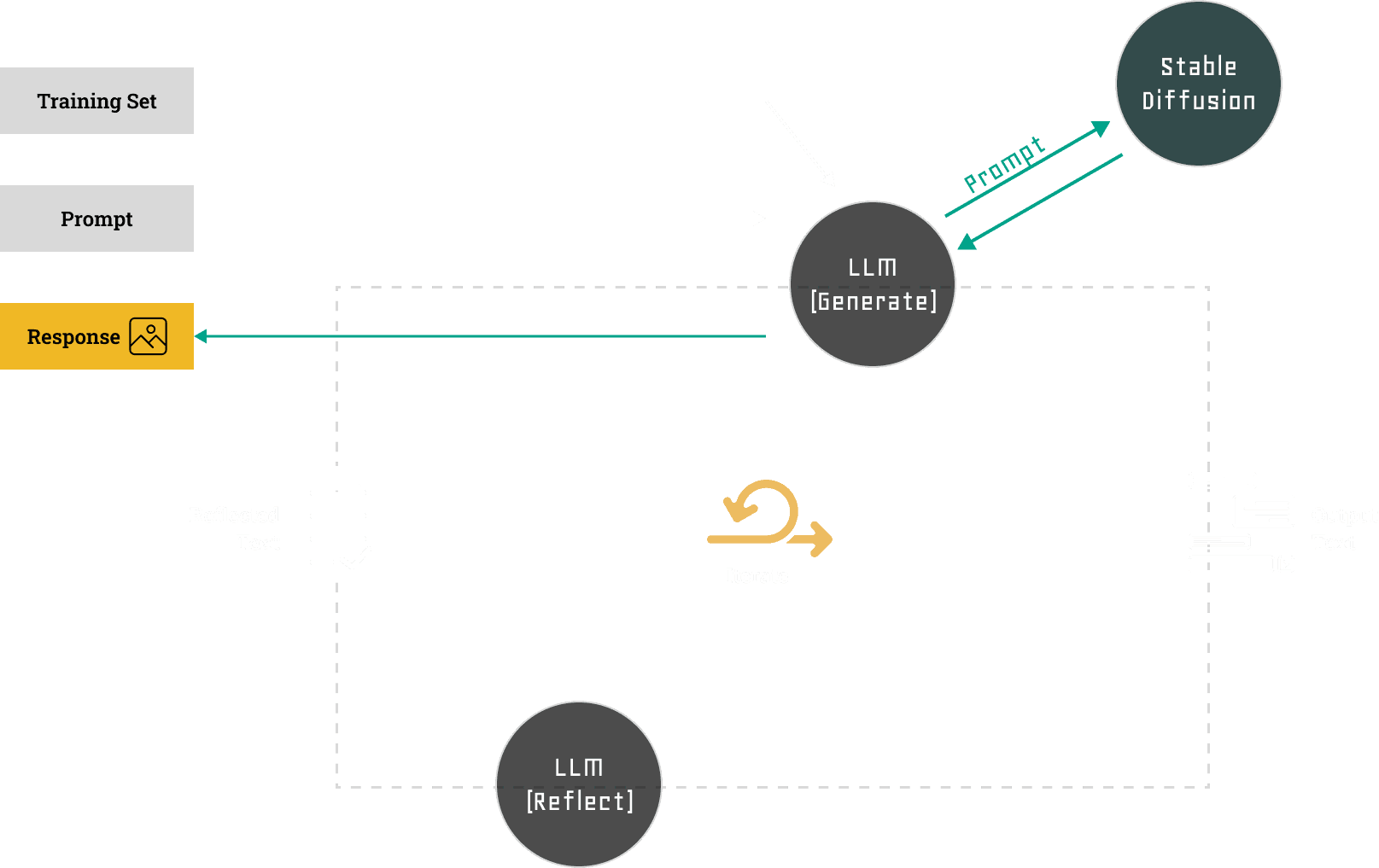
Connected Stable Diffusion via the Automatic1111 API to OpenWebUI — allowing the local LLM to generate Stable Diffusion prompts from a concept. The first local experiment in making two AI systems talk to each other without any cloud involvement.
Designing Agentic Personas
Built role-specific agents within OpenWebUI: a Content Writer for project descriptions, a Visual Prompter for SD-friendly image prompts, and a Design Researcher for brief analysis. Each had its own system prompt and task orientation, treating agent design as interface design.
INTRODUCTION
Running LLMs locally on Apple Silicon and connecting them to Stable Diffusion started as infrastructure curiosity. It became a production tool: one of four active Investigation Zone missions at MuSo was first-drafted by the trained model, and the first draft of Lost Code of Play came out of the same system.
This is how it was built.
SETTING UP THE LOCAL STACK
I started with Ollama — a tool that makes it surprisingly seamless to host LLMs like LLaMA 3, DeepSeek, Qwen, and Phi locally, using Apple Silicon’s GPU acceleration. Paired with OpenWebUI, an open-source ChatGPT-style interface, I created a self-contained sandboxed chat environment: private, responsive, and fully modular.
The result was a system where I could run multiple models simultaneously, switch between them mid-conversation, and build a UI layer with account handling, prompt storage, and system prompt configuration.
The biggest benefit: nothing was going online. No computation on the cloud. No privacy risk. No data leakage. For a museum working with unpublished exhibit content, this mattered enormously.
CONTEXTUAL PRIMING
Once the environment was running, I began feeding foundational MuSo documents into the LLM’s prompt memory — project briefs, space design philosophies, mission structures, and tone-of-voice guides.
This wasn’t fine-tuning in the traditional sense. It was contextual priming: turning a general-purpose model into a MuSo-aware creative partner fluent in the specific language and logic the team had spent years developing.
I could ask the model:
- Generate five narrative formats for a spatial experience about climate justice
- Suggest variations on our Coral Mission for a travelling exhibit
- Draft a quiz structure for a water conservation challenge
These weren’t templated outputs. They carried the tone, cadence, and conceptual vocabulary that the team had built over years of exhibit design.

CONNECTING TWO AI SYSTEMS
To push the experiment further, I connected Stable Diffusion (via the Automatic1111 API) to the OpenWebUI setup — allowing the local LLM to generate image prompts from a concept, which were then forwarded to Stable Diffusion for rendering.
My first successful attempt at making two local AI systems talk to each other, with no internet in between.
The results varied. Sometimes the LLM wrote prompts that were too abstract or not SD-friendly, producing uncanny or irrelevant visuals. But when it clicked, it felt genuinely generative: a co-pilot typing ideas while another sketched them into existence.

DESIGNING AGENTIC PERSONAS
Rather than relying on a general assistant, I began building role-specific agents within OpenWebUI — each with its own persona, system prompt, and task orientation.
- Content Writer: formatted project descriptions with clarity and consistent tone
- Visual Prompter: adapted concepts into clean, Stable Diffusion-friendly prompts
- Design Researcher: analysed briefs and surfaced considerations the team might have missed
The more I iterated, the more clearly I saw: agent design itself is an act of interface design (just invisible). You’re designing the conditions for meaningful interaction, not the interaction itself.
IMPACT
One of four active missions in the Investigation Zone at MuSo’s DISCOVER LAB was first drafted by this trained model. It operates within the Investigation Zone Game System, one of my other projects.
The first draft of the newly launched Lost Code of Play was also produced by this system — managed by a Vibe-coded Score & Leaderboard System I built separately. All of this is part of the Summer@MuSo programme.
REFLECTION
What worked:
- Speed: iteration was fast enough to go from thought to draft to prototype in hours
- Contextual relevance: with smart prompt scaffolding, the model mirrored internal logic impressively well
- Agency: the system wasn’t passive; it became an active provocateur in ideation
What didn’t:
- Memory limitations: long, layered queries lost context across threads
- Context drift: contextual priming worked most of the time, but not always
The more useful skill demonstrated here isn’t prompt engineering. It’s system design. Building an environment where AI outputs are usable requires knowing what role each model should play, how to structure context for reliability, and when a human judgment call overrides the draft. This lab was the testbed for that thinking, and it shipped real work.